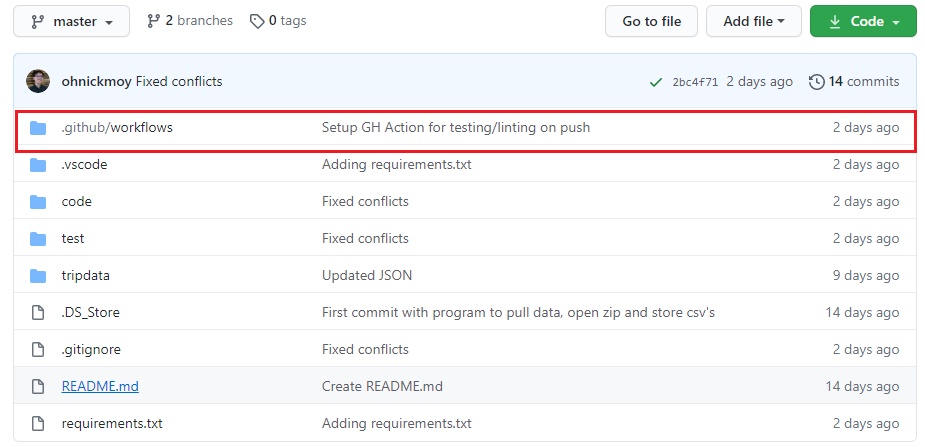
Testing my code was drilled into my brain when I was working at edX. For each monitoring script I wrote, there was an accompanying test script to make sure that it worked. Prior to edX, I admittedly did not write tests for my code to make sure it worked. I just relied on good ol’ pencil and paper, have a list of what I wanted to check, and manually test code for outcomes.
So write code, have some test inputs, run the code, check for errors and outcomes. Wash, rinse, repeat.
Admittedly, the above wasn’t efficient, but it’s what I knew. In Flatiron School, we touched upon writing tests for our code. Even our practice assignments had tests to along with them. Shameless green! But given the time and learning curve, it was something I put on the back burner. And then work happened and then things changed.
The value of testing code and TDD
For most of us software developers starting out, writing code and testing it afterward was the natural thing to do. TDD, or test-driven development flips that in order. For TDD, according to GeeksforGeeks, test cases are written before the code that validates those cases.
The following sequence of steps is generally followed:
1. Add a test – Write a test case that describe the function completely. In order to make the test cases the developer must understand the features and requirements using user stories and use cases.
2. Run all the test cases and make sure that the new test case fails.
3. Write the code that passes the test case
4. Run the test cases
5. Refactor code – This is done to remove duplication of code.
6. Repeat the above mentioned steps again and again
Hackernoon provides this graphic:
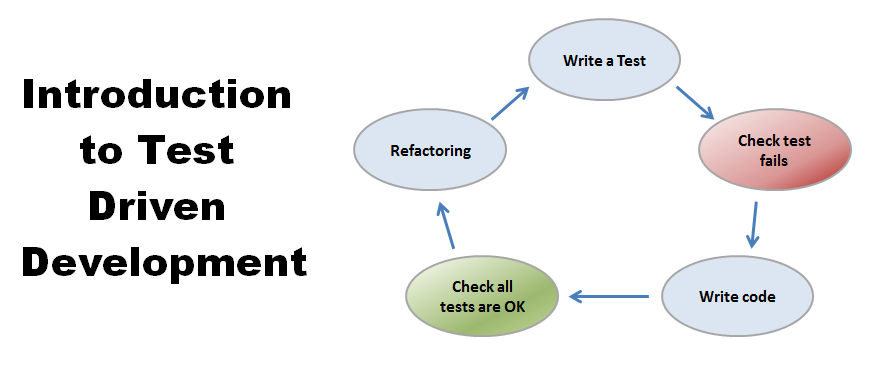
But why is this important?
While TDD isn’t a miracle pill that solves all your code error problems, assuming that you adopt the practice, it does force a change in approach on how to write your code. For me, it forced me to write my code into smaller chunks and identify dependencies within my code. In addition, it forced me to clearly identify what these chunks of code are supposed to do before writing them. If I know beforehand my inputs and assumed outputs, that’ll keep me on track when designing and writing my code for its overall purpose.
On another note, once I’m done with my designing my tests and satisfied with what it does, I’m not as worried about the functionality of my code when I do refactor it, since feedback is pretty clear and quick.
Frameworks of choice
Testing frameworks are more prevalent these days for popular languages. For instance, JavaScript has Jest and Mocha, just to name a few. Ruby has rpsec. Python has it’s own as well, like PyTest, as well as its own built in library, unit test. Since my project runs on Python, we’ll dwelve into more of those.
Testing CovidBikeData scripts with Pytest and unit test
CovidBikeData, my current side project as I look for work, so far has a scraper to pull data and another script to plot some data. Let’s take a look at the scraper code.
Along with the test script that accompanies it
Breaking down the test script
If you recall, the scrapper attempts to pull data from an s3 bucket hosted by Citibike. The data of a given month gets published a month afterward, so that was a clue for me to write a test to account for that. When designing the code to check to see if there’s a new batch of data published (because we’ll never know when Citibike decides to publish data), I opted to save what data was already published into JSON (so the script knows not to redownload data), so I had to do some reading and writing. That was a clue for another dependency, hence a potential test case. Finally, if we downloaded the zip file, we’d have to unzip it, so a third test case.
For all three, I tried to identify what I wanted to test, so you’ll see in the second gist things like checking for the previous month and year, checking for a successful opening of a JSON file, or a successful unzipping of files.
Lines 3 -7 show my imports. I decided to use unit test, since that’s what I was familiar with. I also needed the datetime and os modules, since that was integral to my code. You’ll notice in line 6 a mock package, which I’ll explain in another post, and finally, the code that I’m testing, which I called app.
import unittest
import datetime
import os
from unittest import mock
from scraper import appLet’s look at my first test.
@mock.patch('datetime.datetime')
def test_get_previous_month_with_year(self, mock_date):
"""Test for get_previous_month_with_year
Since Citibike publishes data for a given month the following month, check that previous
month is returned
Args:
mock_date (mock): mock object from the patch decorator that replaces datetime.datetime
within get_previous_month_with_year
"""
mock_date.now.return_value = datetime.date(2020, 11, 20)
test_date = app.get_previous_month_with_year()
self.assertEqual(test_date[0], 10)
self.assertEqual(test_date[1], 2020)I’ll get more in-depth with mocking in an upcoming post, but what the “mock_date.now.return_value” line is doing is replacing the datetime.now in my original function “get_previous_month_with_year()” with a date of 11/20/2020.
Knowing that Citibike publishes data of a given month later, I would check the date of “now”, and then return the previous month and year in a tuple. So if a forced an input of 11/20/2020, I should get an output tuple of (10, 2020).
Those “self.assertEqual” lines then check the values within the tuple.
Since I was going with a TDD approach, the test dictated how the code would be designed, ultimately it became what you see below.
def get_previous_month_with_year():
"""Checks for current month and returns the last month,
since Citibike publishes data of a given month a month later
ex. Data for January is published February
Returns:
tuple: Tuple of previous month and its associated year
"""
now = datetime.datetime.now()
past_month = now.month - 1 if now.month != 1 else 12
year = now.year if past_month != 12 else now.year - 1
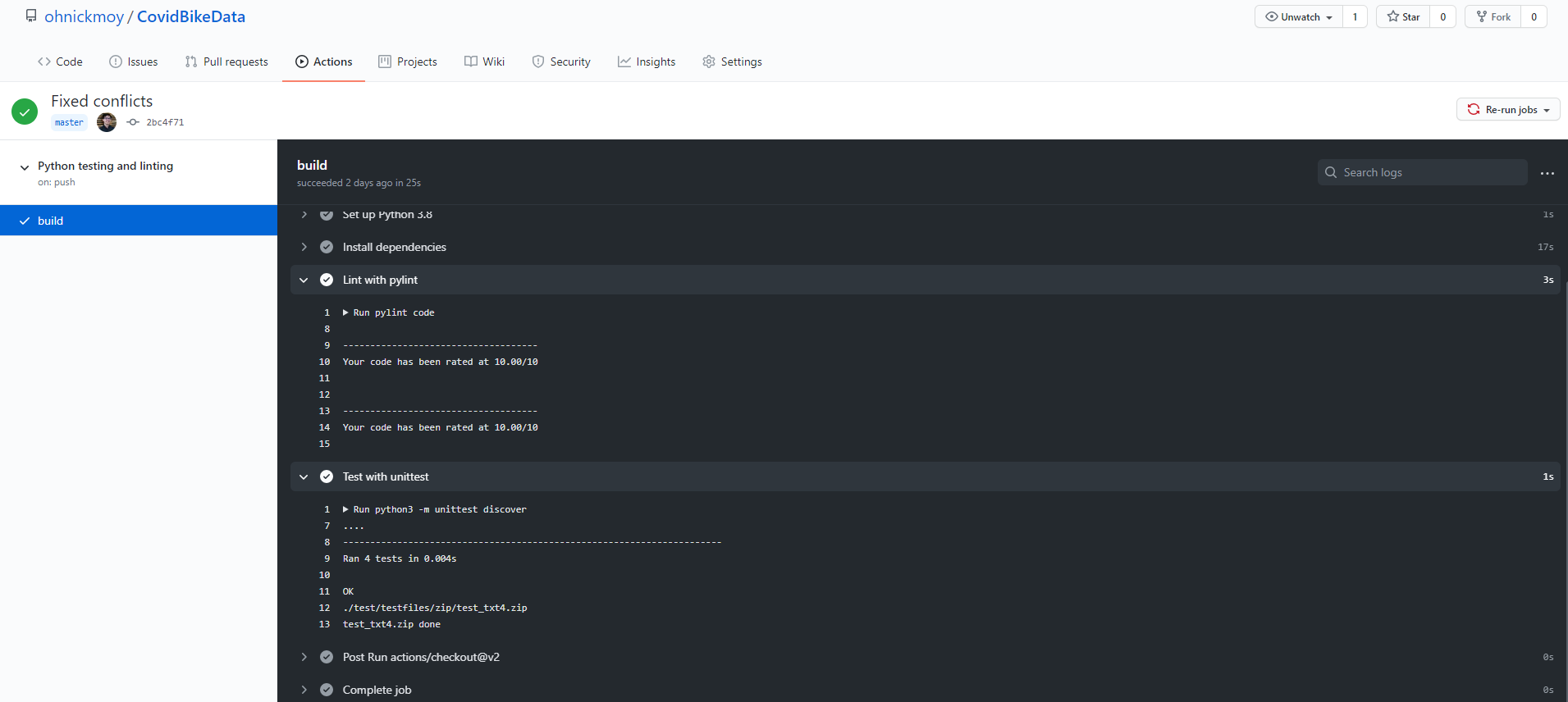
return (past_month, year)I took this approach with the other tests as well. Write a test, and then write a function to account for it. Let’s say I wrote four all tests, and then execute them. Successful tests would look something like below. For each test would be a dot.
....
----------------------------------------------------------------------
Ran 4 tests in 0.004s
OKLet’s say you failed a test, a dot would instead be a big “F”.
When do these tests get executed?
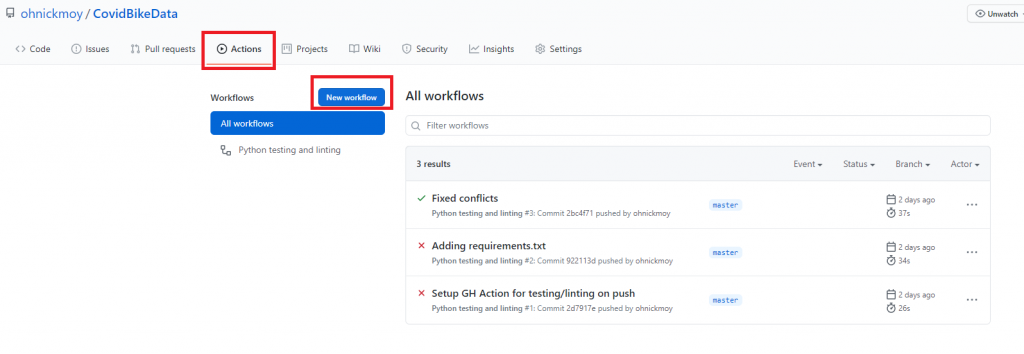
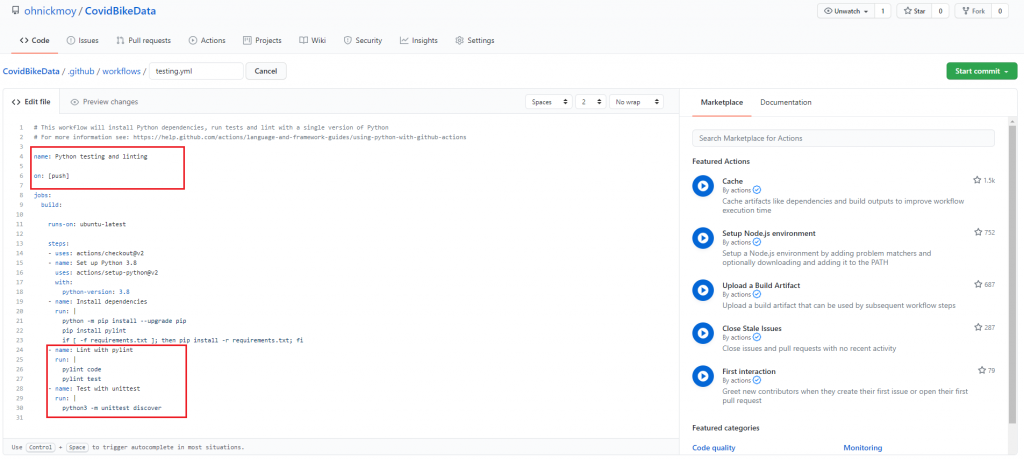
Let’s say you’re the new owner of this code and need to refactor it for some reason, but want to keep the same expected outcomes. These tests, assuming that the previous owner wrote them already, would help you make sure those expected outcomes are still maintained, despite code changes. But how are they executed without you, the new owner, running the pytest command over and over again? That’s where the workflows from GitHub actions come in.
Here’s what it looks like, as a refresher:
name: Python testing and linting
on: [push]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python 3.8
uses: actions/setup-python@v2
with:
python-version: 3.8
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install pylint pytest
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
- name: Lint with pylint
run: |
pylint scraper
pylint plotdata
pylint test
- name: Test with pytest
run: |
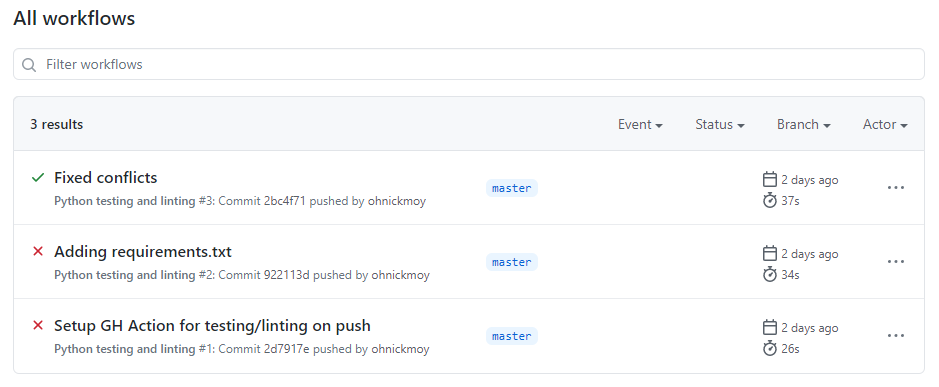
pytestAaaaaaall the way on the bottom is the command to run pytest. This action tells Github to, among other things, run pytest every time new code is pushed onto a branch. Get the tests to past, you get a green check mark, but if it the tests fail, you get a big red x.
The workflows help in some of the automation of testing and getting new code into the code base while preventing faulty builds. A set it and forget it type of thing.
Here’s an example:
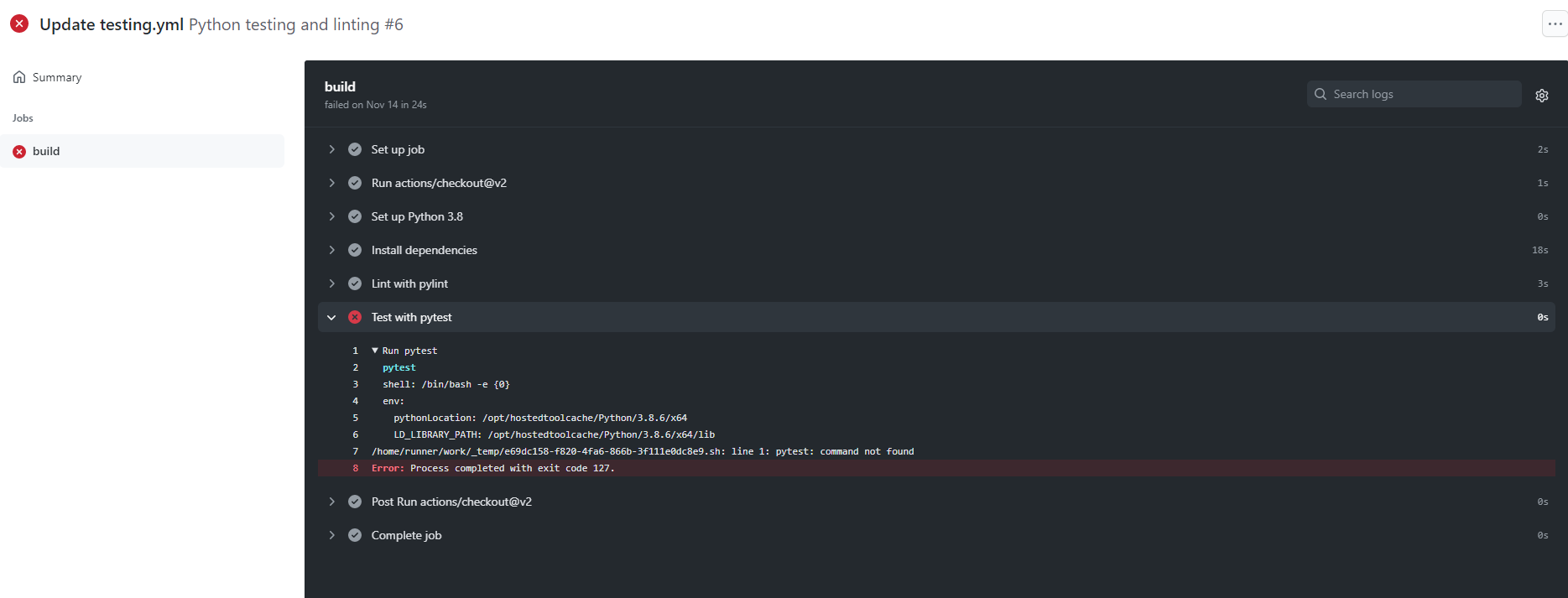
At this point, I was switching over from unit test to pytest, mostly cause a friend of mine said pytest gave you pretty colors. BUT, there are better reasons for using pytest of over unit test and that’s mostly because pytest doesn’t need as much boilerplate code to set up as unit test does. Thankfully, pytest can run unit tests even when old tests are set up to run with unit test. Big win!
Conclusion
That was a brief intro to TDD, some of the python testing frameworks, and how I’m implementing it into my project. Hope it was helpful! Check out the sources and citations of this blog post for more info.